Machine learning has revolutionized data analysis, predictive modeling, and automation. Among the top tools, scikit-learn is one of the most popular and beginner-friendly Python libraries. Built on NumPy, SciPy, and Matplotlib, it simplifies machine learning tasks like classification, regression, clustering, and dimensionality reduction. An intuitive API enables quick model development and testing, making it ideal for both beginners and professionals.
Scikit-learn’s ease of use, consistency, and hassle-free integration with other Python libraries make it the first choice among data scientists. It simplifies difficult tasks and speeds up machine-learning pipelines in research or production environments.
What Makes Scikit-Learn Essential?
Scikit-learn was created to ease machine learning without sacrificing performance. Its greatest strength is its very easy and uniform API, which enables users to specify algorithms using as few as three lines of code. The library comes with some built-in tools for model selection, preprocessing, and validation that decrease manual coding effort. This makes it especially valuable for practitioners who must rapidly test and iterate across models.
Another key strength is its efficiency. Constructed atop NumPy and SciPy, sci-kit relies on optimized numerical computations to manage large data efficiently. Compared to deep learning frameworks that have been optimized for extremely complex neural networks, sci-kit works with traditional machine learning models that are less complex, easier to interpret, and computationally less expensive. It's best suited for applications such as fraud detection, customer segmentation, recommendation systems, and medical diagnosis.
In addition to ease of use and efficiency, scikit-learn also guarantees reliability. The data science community embraces the library and, therefore, is well-supported, frequently updated, and heavily tested. Such reliability is why it's also a good choice for education and business applications.
How Scikit-Learn Works: A Look at Its Core Features
Scikit-learn provides a well-defined interface for building machine learning algorithms, making the development, testing, and deployment of the models much simpler and faster.
Classification: Organizing Data into Categories
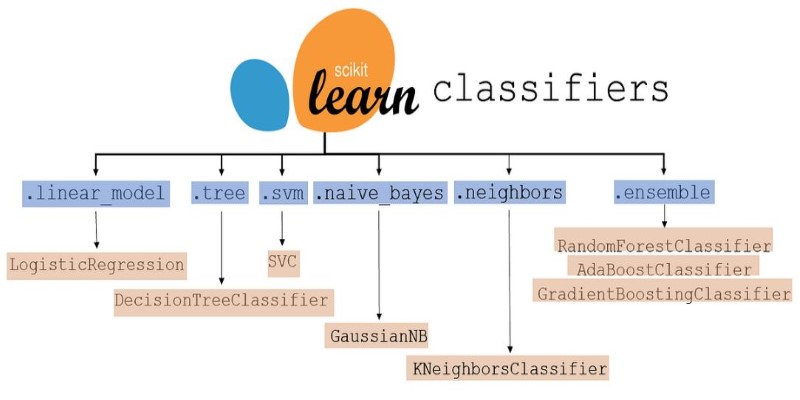
Scikit-learn’s classification algorithms help categorize data into predefined labels. Methods like Support Vector Machines (SVM), Decision Trees, and Random Forests enable accurate predictions for tasks such as spam detection, fraud identification, and medical diagnosis. By learning from labeled datasets, these models efficiently classify emails, transactions, and medical conditions, improving decision-making and automation.
Regression: Predicting Numerical Outcomes
Regression models in scikit-learn predict continuous values, making them essential for financial forecasting, real estate valuation, and healthcare analytics. Algorithms like Linear Regression, Ridge Regression, and Support Vector Regression analyze historical data to establish relationships between variables. This allows users to forecast stock prices, housing costs, and medical expenses, providing valuable insights for business and research.
Clustering: Identifying Patterns Without Labels
Scikit-learn’s clustering techniques, such as K-Means and DBSCAN, group similar data points without predefined labels. These algorithms are useful for customer segmentation, anomaly detection, and pattern recognition. Businesses use clustering to classify customers based on behavior, detect fraud in financial transactions, and analyze genetic sequences, making it a valuable tool for data-driven decision-making.
Feature Selection and Dimensionality Reduction
Scikit-learn includes tools for feature selection and dimensionality reduction to enhance model performance. Principal Component Analysis (PCA) reduces dataset complexity while retaining important information. This is useful for image recognition, speech processing, and genomic analysis, as it improves computational efficiency, prevents overfitting, and ensures better machine learning model performance with large datasets.
Data Preprocessing: Optimizing Data for Machine Learning
Preprocessing ensures raw data is properly formatted for machine learning models. Scikit-learn provides functions like MinMaxScaler, StandardScaler, and OneHotEncoder to handle missing values, normalize numerical data, and encode categorical variables. Proper preprocessing improves model accuracy, prevents inconsistencies, and ensures datasets are optimized, making machine-learning workflows smoother and more effective.
Why Scikit-Learn Is a Preferred Choice for Data Scientists?
Scikit-learn has become a go-to machine learning library due to its ease of use, efficiency, and seamless integration with other tools. It simplifies complex workflows, making it ideal for both beginners and experienced data scientists.
Simplified Machine Learning Workflows
Unlike other libraries that require extensive coding, scikit-learn provides a structured pipeline that streamlines model training and evaluation. Users can implement machine learning models with minimal code, reducing redundancy and making experimentation more efficient. This structured approach saves time and allows for rapid testing of different algorithms.
Seamless Integration with Python Libraries

Scikit-learn is designed to work effortlessly with popular Python libraries. It integrates smoothly with Pandas for data manipulation, Matplotlib for visualization, and TensorFlow or PyTorch for deep learning applications. This compatibility makes it a vital part of the data science ecosystem, ensuring a seamless workflow across different tools and frameworks.
Beginner-Friendly Documentation and Community Support
The library is well-documented, offering comprehensive guides, examples, and best practices. This makes it easier for newcomers to understand and implement machine-learning techniques. Additionally, scikit-learn has an active open-source community where users can seek support through forums, discussions, and contributions, making learning and troubleshooting more accessible.
Efficiency in Handling Small to Medium-Sized Datasets
While deep learning models demand large datasets and significant computational power, sci-kit-learn is optimized for small to medium-sized datasets. This makes it an excellent choice for startups, researchers, and independent developers who may not have access to high-performance computing systems but still need reliable and accurate machine learning models.
Conclusion
Scikit-learn is a powerful yet simple tool that makes machine learning accessible to beginners and professionals alike. With its wide range of algorithms, efficient data handling, and seamless integration with other Python libraries, it remains a top choice for data scientists. Its structured API simplifies workflows, allowing users to focus on improving model performance rather than coding complexities. Whether you're working with classification, regression, clustering, or preprocessing, scikit-learn provides a reliable foundation for machine learning applications. For those looking to explore data-driven solutions, mastering scikit-learn is an essential step toward building effective and scalable machine learning models.